Is Claude Fable 5 as Good as Anthropic Says?
Anthropic's launch numbers are extraordinary. We checked them against independent leaderboards, a famous unsolved math problem, and the model's own failure modes, to separate the capability from the press release.
Update (July 2026): Anthropic suspended Fable 5 and Mythos 5 on June 12th under a US export-control directive, then redeployed Fable 5 globally on July 1st once the controls were lifted. It remains available on the API at standard rates; complimentary access on paid subscriptions is being wound down in a series of short extensions, after which subscription use moves to prepaid usage credits. We cover the wind-down and what it costs here.
On June 9th, Anthropic released Claude Fable 5, which it describes as the most capable model it has ever released to the public.
The headline claim is straightforward: Fable 5 is state-of-the-art on nearly every benchmark Anthropic is showing the public, from coding and agentic work to knowledge and vision. It is also wrapped in a new layer of safety classifiers, which have apparently been causing problems. But what is Fable like without these restrictions? Surprise, it's Claude Mythos. Claude Mythos 5 is Fable without safeguards but Anthropic considers this risky. As such, Mythos is only available to vetted cyberdefenders through Anthropic's Project Glasswing.
Since they're the same model under the hood and Fable is more widely available, it will be the focus of our assessment. Frontier AI launches all have the same problem: the lab grades its own homework. Benchmark contamination, cherry-picked effort settings, and selective reporting are common tricks of the trade. "We ran our model on a test we chose and it won" is a claim to be taken with a grain of salt.
Strip away the press release and is Fable 5 still as good as its benchmarks say? To answer that, we first examine Anthropic's own numbers and compare their results with those found in reputable independent benchmarks, user anecdotes, and our own experiences.
Anthropic's own numbers
By Anthropic's system card, Fable 5 leads its predecessor Opus 4.8, OpenAI's GPT-5.5, and Google's Gemini 3.1 Pro on nearly everything.
Scores from the system card's evaluation summary (averaged over 5 trials).
Perhaps the most striking result is on Cognition's FrontierCode, which tests whether a model can complete hard coding tasks while meeting production-codebase standards. In other words, follow the rules and don't break things.
Pass rates on Cognition's FrontierCode evaluation. (Diamond is the hardest tier.)
Anthropic's headline framing is unambiguous:
"the longer and more complex the task, the larger Fable 5's lead."
An example they provide comes from GraphWalks, a long-context reasoning test. Every model degrades as context grows, just as human memory can only store so much information at once. But different models degrade at different rates:
Accuracy on graph-traversal reasoning at 256K vs. 1M tokens. The slope is the story: Fable/Mythos 5 loses about 12% while GPT-5.5 loses over 28%.
Once again Fable 5 comes out on top. Long-horizon agentic workflows depend on reliable memory so this is potentially a big deal. Fable shows off its memory elsewhere too: given file-based memory to play Slay the Spire, Fable 5 performed around three times better than Opus 4.8 given identical setups.
Impressive. But every number comes from Anthropic. That's the catch. A lab has every incentive to flatter itself and the real test is whether independent benchmarks and real-world experiences concur.
Do the independent benchmarks agree?
Largely, yes. Authoritative independent benchmarks repeatedly place Fable 5 at or near the top of their rankings.
Our findings, at a glance:
Artificial Analysis put Fable #1 on its Intelligence Index at 64.9, about five points clear of the nearest non-Anthropic model. Vals AI and CursorBench showed a similar separation on coding and agentic IDE work:
A useful new benchmark is Agents’ Last Exam, a Berkeley test that focuses less on answering questions and more on doing actual work. It includes more than 1,500 collected tasks across 55 professional subfields. Rather than selecting answers, agents have to use real software, operating through the command line and graphical interfaces, to perform work in realistic scenarios. The published evaluation covers 160 task instances across three difficulty tiers, ranging from tasks today’s agents can plausibly complete to a “Last Exam” tier meant to sit at the frontier of professional work.
ALE evaluates models inside agent harnesses rather than as standalone chatbots, but the three featured models still land in roughly the same cluster:
"Agents' Last Exam" is not to be confused with the similiarly named "Humanity's Last Exam". This benchmark evalutates something different: expert-level academic knowledge. The full benchmark contains thousands of expert-vetted questions across mathematics, science, and the humanities.
Here Fable does not merely join the other frontier LLMs. It finishes first by a clear margin:
A 7.6-point lead over second place. And this result also comes with a caveat that makes this achievement even more impressive: safety guardrails routed 9% of HLE tasks to the weaker Opus 4.8.
Let's look at two more leaderboards. LMArena ranks models by blind human votes rather than a test. LiveBench rotates in fresh, unseen questions every month to avoid being present in AI datasets. Fable lands at or near the top of both.
On LiveBench Fable 5 does not lead but remains near the front of the pack. It also tops the language category, beats every prior Claude model, and on the global average sits fourth in a tightly bunched pack, just ~2.4 points behind GPT-5.5 on extra high effort mode.
So the honest verdict on the benchmark question is reassuringly boring: Fable 5 sits consistently at or near the top across many independent benchmarks. #1 on Artificial Analysis's Intelligence Index and Humanity's Last Exam, Vals, CursorBench, and LMArena's agentic voting; a close fourth in a tightly bunched pack on LiveBench while topping its language category; and second place in Agents' Last Exam.
There's possibly a subtler, quieter win in the speed data too. On Artificial Analysis's throughput test, Fable 5 pushes about 63 output tokens per second (tps): faster than GPT-5.5 at every effort tier, slighyl ahead of Opus 4.8, and behind only Gemini 3.1 Pro among the frontier models. For a model this capable, that's unusually good tps.
That said, tps is not the end-all metric to evaluate speed. An LLM that uses a lot of tokens will be slow even if its token output is quick. The best practitioner write-up we found backs Fable's capability claims up but provides a caveat regarding speed. Simon Willison, the co-creator of the web framework Django, spent Fable's launch day putting Anthropic's model through ordinary builder work. His assessment? Fable was slow, expensive, and unusually capable. Fable can be a lavish token spender and because of this a single task can still take a while end-to-end.
What Fable built for us in 60 minutes
Independent benchmarks and the anecdotal experiences of others look promising. Our next question was "What can Fable build in an hour?" Could it build an environment with Three.js? Over roughly 60 minutes of iterative prompting, Fable produced a 111 KB single-file Three.js game: a procedural autumn forest with custom shaders, generated textures, wind, water, spatial audio, first-person movement, and a ghost-shooting loop.
This isn't a controlled benchmark in any sense of the word, but it is a demonstration of Fable's capabilities. Fable transformed a sequence of requests into a coherent, playable environment in minutes.
Built with Fable 5
Autumn Valley at Sunset
Explore the complete environment in your browser. The hosted build is the artifact Fable produced, with a small CarbonSilicon Labs mark added afterward.
Our experiment tested how quickly Fable could build a game with human direction. Anthropic's Pokémon run tested a harder inverse: whether Fable could operate inside a game without human direction.
The demo you can watch: Pokémon, with its eyes
Anthropic has run a long-standing, deliberately hands-off experiment called Claude Plays Pokémon: Successive models have attempted to play Pokémon Red, equipped with harnesses to assist them in their journey. Despite this, models would inevitably get stuck on some puzzle. For over a year the runs stalled out. Opus 4.0 ground to a halt around the midgame, and Opus 4.5 and 4.6 both couldn't get past Indigo Plateau, just short of the game's final act. That changed last month when Opus 4.7 became the first Claude to finish Red, taking ~259 hours with a harness. Fable 5 was not given a harness. Instead, it was handed raw screenshots of FireRed and a controller (no maps, no harness) and cleared the game in roughly 50 hours, far quicker than Opus 4.7. In fact, 50 hours isn't much slower than a typical human playthrough, which clocks in between 25 and 30 hours.
Before Fable, many Pokémon tasks used to need purpose-built scaffolding to be completable for AI.
 Perception. The model's entire world is a raw 240×160 screenshot. No API, no RAM access.
Perception. The model's entire world is a raw 240×160 screenshot. No API, no RAM access. Spatial reasoning. It builds and holds a mental map across thousands of screens, what earlier models needed pathfinding tools for.
Spatial reasoning. It builds and holds a mental map across thousands of screens, what earlier models needed pathfinding tools for. Tactical planning. Multi-turn decisions: reading HP bars from pixels, applying type matchups, managing resources.
Tactical planning. Multi-turn decisions: reading HP bars from pixels, applying type matchups, managing resources. Goal persistence. Badges, HMs, and route plans tracked across tens of hours without a quest log.
Goal persistence. Badges, HMs, and route plans tracked across tens of hours without a quest log.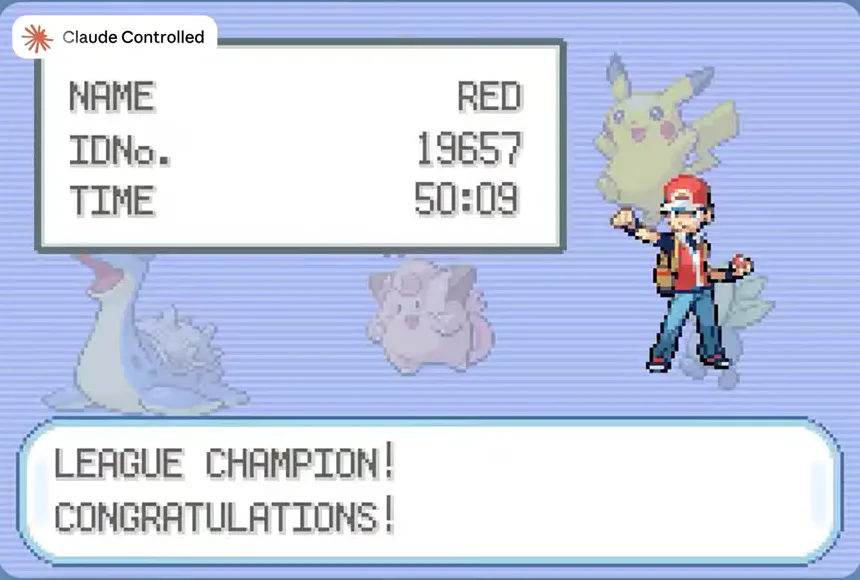 Completion. In-game clock: 50:09, slower than a human's ~25 to 30 hours, but over 5× faster than Opus 4.7, the only earlier Claude to finish at all.
Completion. In-game clock: 50:09, slower than a human's ~25 to 30 hours, but over 5× faster than Opus 4.7, the only earlier Claude to finish at all.- Sonnet 3.7
- Opus 4.0
- Opus 4.1
- Sonnet 4.5
- Opus 4.5
- Opus 4.6
- Opus 4.7
- Avg. Person
- Fable 5 (FireRed)
The shape tells the story. Older models don't just get stuck: their lines bend flat and crawl rightward, meaning they kept burning tokens without making progress. Models routinely spent thousands of hours stuck, never learning how to progress. Newer frontier models advance through the game much more quickly. Fable 5 rolled credits on FireRed in roughly 50 hours. Just months ago, models needed far more time to travel far less. One caveat to note, however, is that Anthropic demonstrated Fable on Pokémon FireRed rather than Red, which earlier Claude models played. The games are similar and the reason for this choice is unknown but perhaps Fable did not perform as well on Red?
Where it falls short
Despite Fable's considerable power, there are still some unknowns and shortcomings. We believe there are five in particular worth your attention.
Several respected independent benchmarks haven't weighed in. At the time of writing this, Epoch AI's FrontierMath (research-level math the labs can't train against) and METR's time-horizon methodology (how long a task a model can complete at 50% reliability) have no published Fable 5 results and neither appears in the system card. The long-horizon story still leans on Anthropic's own evals.
GPT may remain king of mathematics. While benchmarks thus far indicate Fable performs well, there is reason to believe that OpenAI may still have an edge in the domain of mathematics. For one, the bulk of novel contributions to mathematics discovered by AI are made by OpenAI models. The most stunning recent example of this was OpenAI's recent announcement of a disproof for Erdős's unit distance conjecture, a famous problem in higher mathematics that had eluded an answer for some 80 years. But perhaps Fable can turn the franchise around? We directed multiple independent instances of the model to work on Erdős's unit distance problem with a harness in Claude Code. Fable seemed reluctant to try to tackle this question and ultimately was unsuccessful. Fable was not provided internet access and its January 2026 training cutoff meant it was unaware of OpenAI's solution, making this a fair evaluation.
Anthropic claims they got Mythos to independently develop a valid solution to the unit distance problem after news of OpenAI's discovery broke. We were not able to reproduce these results with Fable. It may be that their harness was more robust than ours, or that Fable is more constricted than Mythos. We found it particularly striking how reluctant Fable was to try to tacle an open problem. This may be the result of RL training penalizing the kind of speculation that can easily lead to LLM hallucinations.
The safety filter is trigger-happy, and Anthropic admits it. Fable 5 ships with classifiers that route flagged requests to the weaker Opus 4.8. These classifiers are aggressive and sometimes trigger during benign interactions. This has become a common complaint on social media and one we ourselves hit during ordinary use. Anthropic's warning message indicates they are aware of the high false-positive rate:
This model has measures that flagged something in this session. This sometimes happens with safe, normal conversations. These measures let us bring you Mythos-level capability in other areas sooner, and we're working to refine them. Switched to Opus 4.8.
Independent testing saw the same thing: Artificial Analysis recorded fallback routing on roughly 8% of its Intelligence Index tasks and Vals reported refusals concentrated on bio, cyber, and some knowledge benchmarks. Anthropic says 95%+ of sessions involve no fallback at all, but a ~5% failure rate is not ideal. And if your work brushes against security or science, expect a hefty tax of degraded answers and false positives. Fable also shipped with a second, invisible safeguard that silently degraded its output on frontier-AI-development requests. This was to impede people training rival models but they reversed course within a day after researchers objected. (Dean Ball called it "secret sabotage".) Anthropic apologized for making the wrong trade-off and agreed to make the safeguard visible. Tellingly, it concedes the visible version must "cast a wider net" to compensate for this change. In other words, it will trip even more benign requests.
It doesn't win on every benchmark. To Anthropic's credit, they do not present Fable's performance as a clean sweep. The system card is also candid about a few notable failures. For example, in Andon Labs' Vending-Bench Arena business simulation, Fable 5 finished last in its round and was the only model to initiate unethical price collusion with other agents.
Three agents run competing vending machine businesses in the same simulated location. Average across the round's runs. Higher is better.
It's the most expensive frontier model on the market. At $10 / $50 per million input/output tokens, Fable 5 costs double Opus 4.8 and five times Gemini 3.1 Pro.
Real workloads may widen that gap. Fable seems quite hungry for tokens. Berkeley's Agents' Last Exam comparison puts the model at roughly $15.70 per task. That's about four times GPT-5.5 and nearly twelve(!) times Cursor's Composer 2.5:
Approximate API cost per task reported by ALE's lead researcher. Lower is better.
Artificial Analysis saw the same issue at benchmark scale: its Humanity's Last Exam run cost roughly $2,200, the highest of any model it had evaluated and easily more than double the cost of GPT-5.5's run.
CursorBench's data concurs: Fable 5 Max led the leaderboard in performance but cost about $18 per task, versus $4.37 for GPT-5.5. It can still be cheaper per finished task if it wins in fewer turns, but that's not a given.
Mythos shows what a different configuration can unlock
While most of our attention has been focused on Fable 5, Mythos is worth touching on. With safeguards off, Mythos 5 is, according to Anthropic, the strongest cybersecurity model in the world:
ExploitBench measures end-to-end vulnerability discovery and exploitation. The Firefox row is the fraction of trials producing a full working exploit against a real browser build. This benchmark does not rely on curated test sets, but real world exploits.
The capability ceiling looks extreme. Identifying a working exploit against a current Firefox build in 88% of attempts is more than benchmark vanity. It represents an existential threat to the software world. For now, Mythos is not available to the public, but open-source models aren't far behind. Within 18 months or less, lone hackers will have access to tools as powerful as Mythos 5, if not more so.
The verdict
So, is Fable 5 as good as its benchmarks say? Yes, with honest asterisks. The capability is real and independently corroborated. The asterisks deal with the edges: ALE shows job-level reliability remains far from solved, it's the priciest frontier API, and a cautious filter will occasionally hand your benign request to a weaker model.
Sources
- 01 · Claude Fable 5 and Claude Mythos 5 — Anthropic, Jun 9, 2026
- 02 · Claude Fable 5 / Claude Mythos 5 system card — Anthropic, Jun 2026
- 03 · Claude Fable 5 Launches at #1 on the Artificial Analysis Intelligence Index — Artificial Analysis, Jun 10, 2026
- 04 · Anthropic's Claude Fable 5 evaluated across our benchmark suite — Vals AI, Jun 9, 2026
- 05 · CursorBench 3.1 Benchmark Scores & AI Model Leaderboard — BenchmarkList, Jun 9, 2026
- 06 · Agents' Last Exam — UC Berkeley RDI, Jun 11, 2026
- 07 · Agents' Last Exam live leaderboard — UC Berkeley RDI, Jun 12, 2026
- 08 · Agents' Last Exam launch thread — Dawn Song, Jun 11, 2026
- 09 · Humanity's Last Exam benchmark leaderboard — Artificial Analysis, Jun 12, 2026
- 10 · LMArena Arena leaderboard (Agent category) — LMArena, Jun 11, 2026
- 11 · LiveBench: contamination-resistant LLM leaderboard — LiveBench, Jun 11, 2026
- 12 · Initial impressions of Claude Fable 5 — Simon Willison's Weblog, Jun 9, 2026
- 13 · Vending-Bench Arena — Andon Labs
- 14 · Anthropic Walks Back Policy That Could Have 'Sabotaged' AI Researchers Using Claude — WIRED, Jun 10, 2026
- 15 · FrontierCode — Cognition
- 16 · Pricing — Anthropic docs
- 17 · API pricing — OpenAI docs
- 18 · Gemini Developer API pricing — Google AI for Developers
- 19 · Project Glasswing — Anthropic
- 20 · Task-Completion Time Horizons of Frontier AI Models — METR
- 21 · FrontierMath — Epoch AI
- 22 · Pokémon LLM run tracker: Claude Plays Pokémon — Google Sheets (community-maintained)
- 23 · Insights into Claude Opus 4.5 from Pokémon (progress write-up) — Julian Bradshaw, LessWrong
- 24 · Pokémon FireRed: How Long to Beat — HowLongToBeat
- 25 · Pokémon Red: How Long to Beat — HowLongToBeat
- 26 · An OpenAI model has disproved a central conjecture in discrete geometry — OpenAI, May 2026
- 27 · Integral points on norm-one tori and the Erdős unit-distance exponent — Anthropic, Jun 2026
- 28 · Claude Mythos reportedly solves OpenAI's landmark Erdős problem with a "cute, simple proof" — The Decoder